Appearance
Memory & Cache
메인 메모리는 CPU가 직접 접근하는 주기억장치다.
실행 중인 프로그램의 코드와 데이터, 커널 자료 구조, 파일 캐시 등이 여기에 올라온다.
메모리는 바이트 단위 주소 공간으로 보이지만, 현대 시스템의 실제 관리 단위는 보통 페이지(page) 다. CPU는 가상 주소를 사용하고, 하드웨어와 운영체제가 그 주소를 실제 물리 메모리나 보조 저장장치의 데이터로 연결한다.
MMU (Memory Management Unit, 메모리 관리 장치)
MMU는 가상 주소를 물리 주소로 변환하고 접근 권한을 검사하는 하드웨어다.
MMU의 핵심 역할은 다음과 같다.
- 가상 주소를 물리 주소로 변환
- 페이지 단위 접근 권한 검사(read/write/execute, user/kernel)
- 잘못된 접근이 있을 때 page fault나 protection fault 같은 예외 발생
즉, MMU는 "데이터가 메모리에 없으면 직접 가져오는 장치"라기보다, 현재 접근이 유효한지 판단하고 주소 번역을 수행하는 장치에 가깝다. 필요한 페이지가 아직 메모리에 없으면 CPU가 page fault 예외를 내고, 이후 운영체제가 해당 페이지를 적재한다.
주소 변환 속도를 높이기 위해 MMU 옆에는 보통 TLB(Translation Lookaside Buffer) 가 있다.
MMU와 메모리 보호
프로세스는 서로 독립된 주소 공간을 가져야 한다. 그래서 MMU는 각 페이지의 권한을 검사해 한 프로세스가 다른 프로세스 메모리나 커널 메모리를 함부로 건드리지 못하게 한다.

base/limit 레지스터는 메모리 보호를 설명할 때 자주 나오는 고전적인 모델이다.
- base 레지스터: 프로세스가 사용할 수 있는 시작 주소
- limit 레지스터: 접근 가능한 범위의 크기
base <= x < base + limit이 모델은 개념 이해에는 좋지만, 현대 범용 운영체제는 보통 페이지 테이블 + 페이지별 권한 비트로 보호를 구현한다. x86-64 같은 환경에서는 세그먼테이션보다 페이징이 훨씬 중심적인 메커니즘이다.
메모리 과할당(Overcommit)
프로세스들이 확보한 가상 메모리 총량이 물리 메모리보다 커질 수 있는 상태
현대 운영체제는 모든 가상 메모리를 즉시 물리 메모리에 대응시키지 않는다. demand paging, 파일 캐시, copy-on-write, swap, overcommit 정책을 조합해 메모리를 더 유연하게 사용한다.
예를 들어 Linux에서는 메모리 할당 성공이 곧바로 "RAM이 이미 확보됐다"는 뜻이 아닐 수 있다. 실제 물리 메모리는 그 주소가 참조되는 시점에 필요해진다.
하지만 메모리 압력이 심해지면 커널은 다음과 같은 순서로 대응한다.
- 비어 있는 프레임이나 재활용 가능한 페이지가 있는지 확인
- 파일 캐시처럼 다시 읽어올 수 있는 clean page를 우선 회수
- 필요하면 dirty page writeback 또는 anonymous page swap-out 수행
- 그래도 부족하면 더 적극적인 reclaim을 수행
- 최악의 경우 OOM(Out Of Memory) 처리로 일부 프로세스를 종료
즉, 현대 시스템은 "프로세스 하나를 통째로 swap out해서 공간을 만든다"기보다 페이지 단위 reclaim을 먼저 수행한다.
페이지 교체(Page Replacement)
빈 프레임이 없을 때 victim page를 골라 프레임을 재사용하는 과정
일반적인 흐름은 다음과 같다.
- 프로세스가 어떤 가상 주소를 참조한다.
- 해당 페이지가 메모리에 없으면 page fault가 발생한다.
- 커널은 유효한 접근인지 확인한 뒤, 빈 프레임이 있으면 바로 페이지를 적재한다.
- 빈 프레임이 없으면 victim page를 선택해 회수한다.
- victim이 dirty면 writeback 또는 swap-out이 필요할 수 있다.
- 새 페이지를 적재하고 페이지 테이블을 갱신한 뒤, fault 난 명령을 다시 실행한다.
여기서 핵심은 "프로세스 전체를 내보내는 것"이 아니라 페이지 단위로 메모리를 회수하고 다시 매핑하는 것이다.
오버헤드를 줄이는 방법
방법 1. dirty bit(변경 비트) 활용
- dirty bit가 set이면 메모리 내용이 backing store와 달라졌다는 뜻이라 writeback이 필요할 수 있다.
- dirty bit가 clear이면 clean page이므로 그냥 버릴 수 있는 경우가 많다.
그래서 clean page를 회수하는 편이 보통 더 저렴하다.
방법 2. 접근 패턴을 반영한 교체 정책 사용
FIFO, LRU 같은 교재용 알고리즘이 대표적이며, 실제 커널은 accessed/reference bit와 working-set 추정, active/inactive list, multigenerational LRU 같은 근사 기법을 사용한다.
캐시 메모리
CPU와 메인 메모리의 속도 차이를 줄이기 위한 고속 기억장치
CPU는 같은 데이터를 반복해서 참조하는 일이 많다. 캐시는 최근에 사용한 데이터와 인접 데이터를 저장해 두었다가, 다음 접근 시 DRAM까지 내려가지 않고 빠르게 응답한다.
- 메인 메모리: DRAM
- 캐시 메모리: 주로 SRAM 기반
현대 CPU는 보통 L1, L2, L3처럼 여러 단계의 캐시를 둔다.
CPU와 기억 장치의 상호작용
- CPU가 가상 주소로 명령어나 데이터를 요청한다.
- TLB와 캐시에서 먼저 찾는다.
- 있으면 hit, 없으면 더 하위 계층으로 내려간다.
- 마지막까지 없으면 메인 메모리에서 캐시 라인 단위로 가져온다.
- 해당 주소가 유효하지 않거나 페이지가 메모리에 없으면 예외(page fault)가 발생한다.
즉, 캐시 miss와 page fault는 다른 개념이다.
- 캐시 miss: 데이터는 메모리에 있지만 캐시에 없음
- page fault: 해당 가상 페이지가 현재 메모리에 없거나 접근 권한이 없음
지역성(Locality)
프로그램은 모든 주소를 균일하게 쓰지 않고, 일정 구간을 반복해서 참조하는 경향이 있다.
- 시간 지역성(Temporal Locality): 최근에 참조한 데이터는 곧 다시 참조될 가능성이 높다.
- 공간 지역성(Spatial Locality): 어떤 주소를 참조하면 그 근처 주소도 곧 참조될 가능성이 높다.
이 성질 덕분에 캐시와 페이지 교체 정책이 효과를 낼 수 있다.
캐시(Cache)
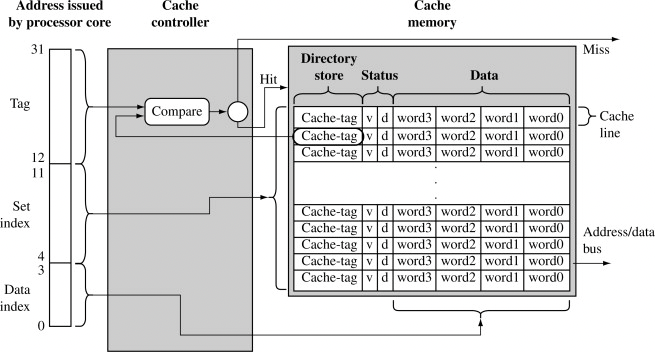
CPU가 메모리를 접근할 때 이렇게 나뉜다(Tag / Index / Offset):
- Tag: 캐시에 이 데이터가 맞는지 확인용
- Set index: 어떤 캐시 줄(Set)에 접근할지 결정
- Data index (offset): 캐시 라인 안에서 어느 데이터 선택할지
캐시 라인(Cache Line)은 캐시와 메모리 사이에서 이동하는 고정 크기 블록이다. 많은 현대 CPU에서 64바이트가 흔하지만, 크기는 아키텍처마다 다를 수 있다.
캐시는 두 부분으로 나뉜다.:
Directory (메타데이터)
각 캐시 라인마다 있음
- Cache-tag: 저장된 데이터의 주소 정보
- v (valid bit): 유효한 데이터인지
- d (dirty bit): 수정된 데이터인지 (write-back용)
Data (실제 데이터)
- word0 ~ word3 → 하나의 캐시 라인(block)
- 한 번에 여러 데이터(word)를 가져옴
즉, 캐시는 바이트 하나씩 가져오지 않고 보통 캐시 라인 단위로 데이터를 적재한다. 그래서 인접한 주소가 함께 빨라지는 공간 지역성이 중요하다.